Compressing gate delays to meet the critical path timing starting with a stage effort f=3.6
The patent describes an algorithm for adjusting the fixed delays of gates in order to reduce delay (by gate compression) or reduce area (by gate stretching). It works successively on the critical paths, from the slowest to the fastest.We will set a desired max delay of 350ps. The critical path is evaluated first, in our case between pins a(1) and s(3). When timed with a stage effort of 3.6, the path delay is 371ps, which gives a negative slack of 21ps. The preferred approach is to divide the negative slack equally between the critical path gates, which are instances a1n, c1a, c2a and s3.
Each gate has a timing equation of the form d = τ × (p + gh) = τ × (p + g × COUT /CIN). When the value of delay d is changed, this is handled by changing the value of CIN. This new value of CIN then alters the value of the previous gate's COUT, and in this way the gates are retimed starting from the output and working to the input.
Following this gate compression, the delay from a(1) to s(3) is now 350ps, but between pins b(1) and s(3) it is 352ps. Reducing the delay of instance a1n by 5ps has made the b(1) input critical, so this too must also be retimed. Then the final critical path becomes:
| CIN | a1n | c1a | c2a | s3 | delay | |
|---|---|---|---|---|---|---|
| old | 31 | 70 | 103 | 89 | 109 | 371 |
| new | 36 | 65 | 97 | 85 | 103 | 350 |
So reducing the critical path delay from 371ps down to 350ps gives an increase in the capacitance of pin a(1) from 31fF to 36fF. This timing is fixed. Any change in the internal net capacitances is handled by increasing or decreasing the input pin capacitance of the gates. In fact, the final pin capacitance on pin a(1) is 33fF instead of 36fF because the parasitic load of gates off of the critical path can be reduced … in particular instance xn1.
Compressing or stretching gate delays on the other paths
The critical paths are timed in succession. If they are slower than the spec, then the gate delays are compressed. If they are quicker, then they are stretched. Once a gate has been timed, it is locked. Other quicker paths which use that gate will be retimed only on the arcs before or after the locked gate.The algorithm sequences are shown below. Negative slacks require timing compression; positive slacks stretching.
| stage effort ρ=3.6 | stage effort ρ=5.4 | ||||
|---|---|---|---|---|---|
| arc | slack | instances | arc | slack | instances |
| a(1)-s(3) | -21 | a1n,c1a,c2a,s3 | a(1)-s(3) | -98 | a1n,c1a,c2a,s3 |
| b(1)-b1n | -2 | b1n | b(1)-b1n | -21 | b1n |
| a(0)-c0 | 2 | c0 | a(0)-s(2) | -71 | c0,c1,c1n,s2 |
| b1n-s(2) | 4 | c1,c1n,s2 | c1-s(4) | -34 | c2,s4 |
| c1-s(4) | 5 | c2,s4 | a1n-s(1) | 10 | xn1,s1 |
| a1n-s(1) | 50 | xn1,s1 | a(0)-s(0) | 65 | c0a,s0n,s0 |
| a(2)-xn2 | 98 | xn2 | a(2)-xn2 | 75 | xn2 |
| a(3)-xn3 | 104 | xn3 | a(3)-xn3 | 81 | xn3 |
| a(0)-s(0) | 125 | c0a,s0n,s0 | a(3)-nr3 | 143 | nr3 |
| a(3)-nr3 | 166 | nr3 | a(3)-nd3 | 170 | nd3 |
| a(3)-nd3 | 192 | nd3 | |||
False critical paths through weak drive strength cells
As a result of retiming the gates, there are now many parallel critical paths. These are highlighted in blue in the top schematic Fig 5a to the right. When the constant delay model is mapped to a real library, the critical path could then become any of these parallel paths. A risk is that paths using weak drive strength cells that are not really critical become critical. This is likely because the weaker cells have a relatively high parasitic capacitance and and tend to be slower than the estimated delay, which is based on an average for all the drive strengths.This can be seen in the second schematic Fig 5b on the right. The critical path now passes through a minimum drive strength 2-XNOR gate.
Another risk is inaccurate timing from non-inverting
cells with a high gain
(=COUT /CIN ).
The fixed timing methodology
loses accuracy for non-inverting cells with a high gain.
The solution here is to set a limit on the gain. This is
useful also for the inverting cells, using the
max_capacitance parameter from the .LIB
file. If HMAX is the maximum gain, then
for inverting cells:
HMAX = max_capacitance/CIN
For non-inverting cells we set HMAX to a limit still giving sufficient accuracy. A value of HMAX = 5 has been used for the vsclib. This raises the drive strength of the 2-XNOR gate, instance xn3, from x05 up to x1 as shown in the third schematic on the right, Fig 5c. Now the false path from a(3) to s(3) has gone, but the path from a(0) to s(0) at 351ps remains. This is caused by the extra parasitic delay of weak drive strength cells, but is close to the design spec of 350ps.
The patent briefly refers to the usefulness of "maintaining a small amount of slack in order to compensate for downstream delay effects such as wire delay". The problem here though is the larger delay shown by weak drive strength cells because of their relatively higher parasitic capacitances.
Compressing gate delays to meet the critical path timing starting with a stage effort f=5.4
When the gates' timing is compressed and stretched starting with an initial stage effort of f=5.4, a limitation or imprecision in the description of the timing methodology becomes apparent. According to the patent, the critical paths are evaluated in order. The first two critical paths are shown below.
| 1st path | a(1) | a1n | c1a | c2a | s3 | slack | ||
| full path | per stage | |||||||
| initial | 0 | 87 | 208 | 315 | 441 | -91 | -23 | |
| final | 0 | 65 | 182 | 266 | 370 | -20 | ||
| 2nd path | b(1) | b1n | c1 | c1n | s2 | slack | ||
| full path | per stage | |||||||
| initial | 0 | 87 | 205 | 292 | 418 | -68 | -17 | |
| final | 0 | 70 | 184 | 254 | 363 | -13 | ||
The timing compression on the second critical path has set the timing of instance b1n at 70ps. This is not the right value. The slack of -20ps remaining on the critical path from a(1) to s(3) is caused by the delay of instance b1n driving c1a, and instance b1n needs to have its timing compressed by 20ps not 17ps. So the criterion for choosing which critical path to compress or stretch is the slack per stage and not the full path slack.
The patent description is "The invention operates on a path-by-path basis whereby the most critical path in a digital circuit is evaluated first. … The invention will then evaluate the next critical path, whereby gate delays may be stretched or compressed." This could mean using the slack per stage to determine the critical path, and this will be done anyway in the examples here in order to achieve the desired result.
The final netlist starting with a stage effort of 5.4 and correctly choosing the critical paths in order is the same as the netlist starting from a stage effort of 3.6.
Final netlist result
The patent describes an algorithm which starts with fixed timing based upon a stage effort of 3.6 for every gate (Fig 4a), and then compresses or stretches the gates' timing to meet critical path requirements or reduce area (Fig 5a). Each gate's timing corresponds to an input capacitance and to an area based upon an area coefficient CS. The area is used to select the nearest cell from the library and give the final circuit timing with the library data (Fig 5b). A gain limit can be used, especially for non-inverting cells, to improve the accuracy of the mapping and avoid false critical paths (Fig 5c).The algorithm works on successive critical paths and is imprecise in the method for choosing the critical path.
The stage effort should be the best stage effort which leads to the minimum delay. This can be found from a library analysis which would give a value of 5.4 for the vsclib. The patent does not do this library analysis, but instead uses a value of 3.6. However the value of the starting stage effort does not appear to affect the final netlist and probably any sensible value could be used.
The areas of each cell are estimated from the fixed delays, and in some way not described in the patent, the areas are mapped to an appropriate drive strength (Fig 5b and Fig 5c). If the mapping is good and the library has been well designed, then there is a close match in timing to the ideal (compare Fig 5b to Fig 5a). Good mapping requires limiting the gain of non-inverting transistors and compensating for the higher parasitic delays of the weaker drive strength cells.
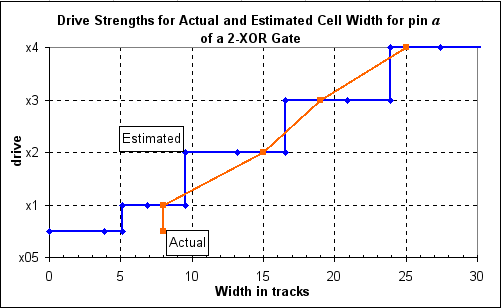
A single area coefficient CS, does not provide a good fit of the cell area to the drive strength (graph on the right). This means that some of the drive strengths are not optimum. Later we will look at an improved mapping using two area coefficients instead of one.