Background to the report
This paper examines the claims made by Magma in U.S. patents numbers 6,453,446 and 6,725,438, but especially 6,725,438 which is basically a revised version of the earlier one (for example the drawings are exactly the same) and was issued after the publication of the book Logical Effort, Designing Fast CMOS Circuits, used here as a reference for the prior art.Magma wrote a letter to Synopsys on July 1, 2004 using language that suggested that they owned the rights, by virtue of having been granted patents, to using a gain based delay model for synthesis. Since logic design based on the gain of logic gates, also known by the name of logical effort, has been known since at least 1991, the originality of the patent disclosure is not obvious. This paper compares the methods of the patent and prior art to discover what is new.
This web site has the full source of a 0.13-micron standard cell library which is used in a 4-bit adder example. The delay is set to 350ps driving 35fF with a maximum input capacitance of 35fF.
Prior art and patent methods for sizing standard cells
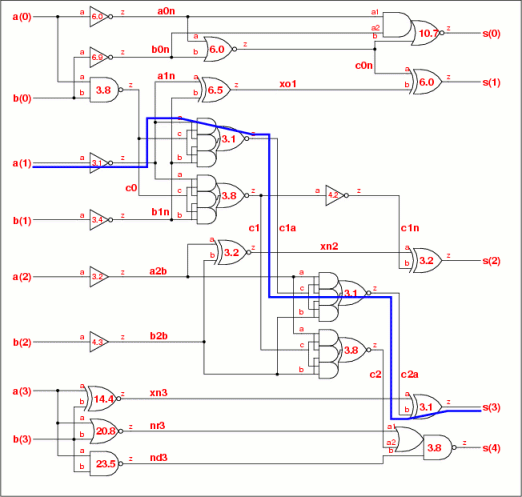
The patent describes a method for sizing the standard cell gates of an integrated circuit. Analysis shows that the patent and the prior art are both using the theory of logical effort to size the cells, and in particular setting an equal stage effort for gates along a path.The difference lies in the way this is done. Prior art finds the path effort delay (the part of the delay that depends on the load) and the number of stages, and divides the delay evenly between the stages as shown in Fig 10a on the right. In the language of logical effort theory, the stage effort of gates along a path is made equal. Working backwards from the outputs, the stage effort is used to find the input capacitance of each gate, and this is used to select the nearest library cell (here the one with the next highest capacitance).
The patent algorithm assigns an initial timing using an arbitrary stage effort as shown in Fig 10b on the right, and then adjusts the timing evenly across all the gates in a critical path. The patent analyses the library to find a coefficient linking the area of a cell to its delay. This is used to estimate the cell area from its delay and to select the cell with the nearest area from the library.
This coefficient means that estimates of the circuit area are a direct function of the delay. With the prior art, area can only be estimated by using a gate's input capacitance to select the nearest library cell.
The two methods choose the standard cells in different ways, one by the input capacitance and the other by the estimated area. This can lead to different cells being chosen, so that even if the theory is the fundamentally the same, in practice the final schematic can be different.
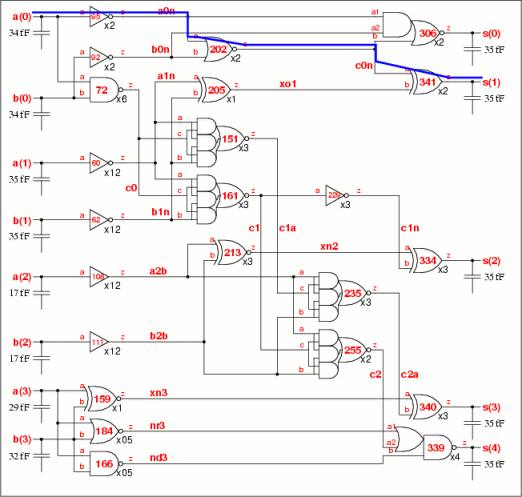
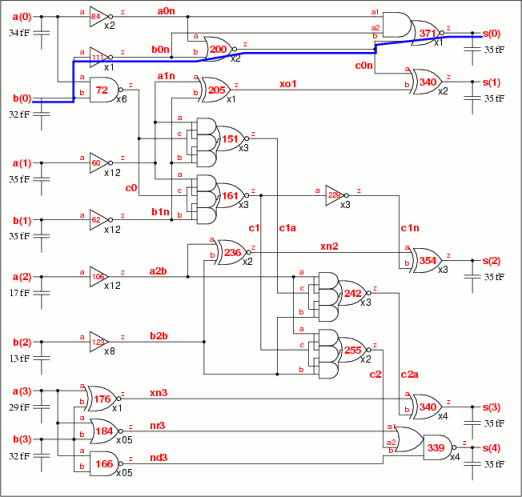
The prior art method produces the schematic shown in Fig 10c with a 341ps critical path, 35fF maximum input capacitance using 89.3 gates. The patent algorithm produces the schematic shown in Fig 10d with a 371ps critical path, 35fF input capacitance using 86.7 gates. The principal schematic differences are in the size of instances b0n and s0. These are too weak in the patent schematic, and this is the cause of the timing requirement not being met.
Patent claims
The theory of logical effort is used by the patent to fix the cells' delay, and this has been known as a logic design methodology since at least 1991. What is new in the patent is:| 1. | The use of an arbitrary stage effort for initial timing and then adjusting it by compressing or stretching delays, rather than calculating each cell's stage effort by directly using the path parasitic delay. | |
| 2. | Linking area to delay by a single area coefficient so that area estimates can be made without using lookup tables to the library information. | |
| 3. | Using the area estimate of each cell instead of the input capacitance to select the cells from the library. |
The patent makes other claims mainly concerned with using the area estimates during place and route of the standard cells. These claims are not directly concerned with producing the netlist, and are applicable to larger circuits than the 4-bit adder, and so have not been considered in this report.
Final netlist quality
Both the patent and prior art algorithms produce final netlists which meet the spec or nearly. The patent algorithm can be made to meet the spec by increasing the output load, say by 20% to 42fF. These netlists though can be manually improved, and this has been done to achieve a better result as shown below in Fig 10e.
Fig 10e. 4-bit adder after manual improvements.

This solution meets all timing specs but uses only 82.7 gates instead of 86.7 for the patent and 89.3 for the prior art methods. The reason why the automated methods do not produce the best netlist is the mapping to the standard cell library. Some cells have been chosen which are stronger (and bigger) than needed. If the mapping algorithm is adjusted to favour weaker cells, these appear in undesired locations (for example the s0 output becoming weaker).
The problem is to find a mapping algorithm to the standard cell library which does not select cells which are too strong, and yet avoids choosing weaker cells which have higher parasitic delays. Neither the patent, nor the prior art in the book Logical Effort teach the solution to this.
Conclusions
| The patent describes an alternative method,
based on estimated cell areas, for using
a gain based logic design methodology to size the
gates in a standard cell design. It does not make any
claims for the prior art methodology which is based
on using gate input capacitances to size the cells.
For the 4-bit adder used to test the methods, the method of the prior art produced a slightly better netlist than the patent. Both methods had a common problem of the mapping to the cell library, caused by variations of individual cells from the average, the higher parasitics of weaker drive strength cells and how to handle non-inverting cells. This meant that both methods gave an inferior result to a manual improvement. The real benefit of gain based synthesis, or using the method of logical effort as it is also known, is the simplification of the problem which allows a quick identification of a nearly right solution. Whether one uses input capacitances or estimates of cell areas to make the cell selection is a question of style, and for the area solution the need to get a Magma licence, but the results are similar. A benefit of the Magma patent is a more efficient way of evaluating the impact of different gate choices on the total circuit area. Since the patent only describes an alternative area-based method for gain based synthesis, it was perhaps a little cheeky of Magma to write so pompously to Synopsys when there was every possibility that Synopsys's solution used existing prior art or new ideas of their own. But equally, given that the patent only describes an alternative to a known design methodology, it is difficult to believe that Synopsys has been severely damaged if it is true that the patent belongs to them and was misappropriated by Magma. Any damage was more likely caused by their own slowness in incorporating publicly available information on the method of logical effort into their own synthesis tool. |